Comet Blog

How Comet Achieved Zero Downtime
Introduction In an era where developers and engineers are constantly evaluating and adopting cloud tools, one of the most important…
Introduction In an era where developers and engineers are constantly evaluating and adopting cloud tools, one of the most important…
In this article, we’ll leverage the power of SAM, the first foundational model for computer vision, along with Stable Diffusion,…

In this article, we’ll compare the results of SDXL 1.0 with its predecessor, Stable Diffusion 2.0. We’ll also take a…

We have changes everywhere. Linkedin, Medium, Github, Substack can be updated everyday. To be able to have or Digital Twin…

We have data everywhere. Linkedin, Medium, Github, Substack, and many other platforms. To be able to build your Digital Twin,…
On March 13, 2024, the European Parliament passed the EU AI Act to establish a common regulatory and legal framework…
→ the 1st out of 11 lessons of the LLM Twin free course What is your LLM Twin? It is an AI character…

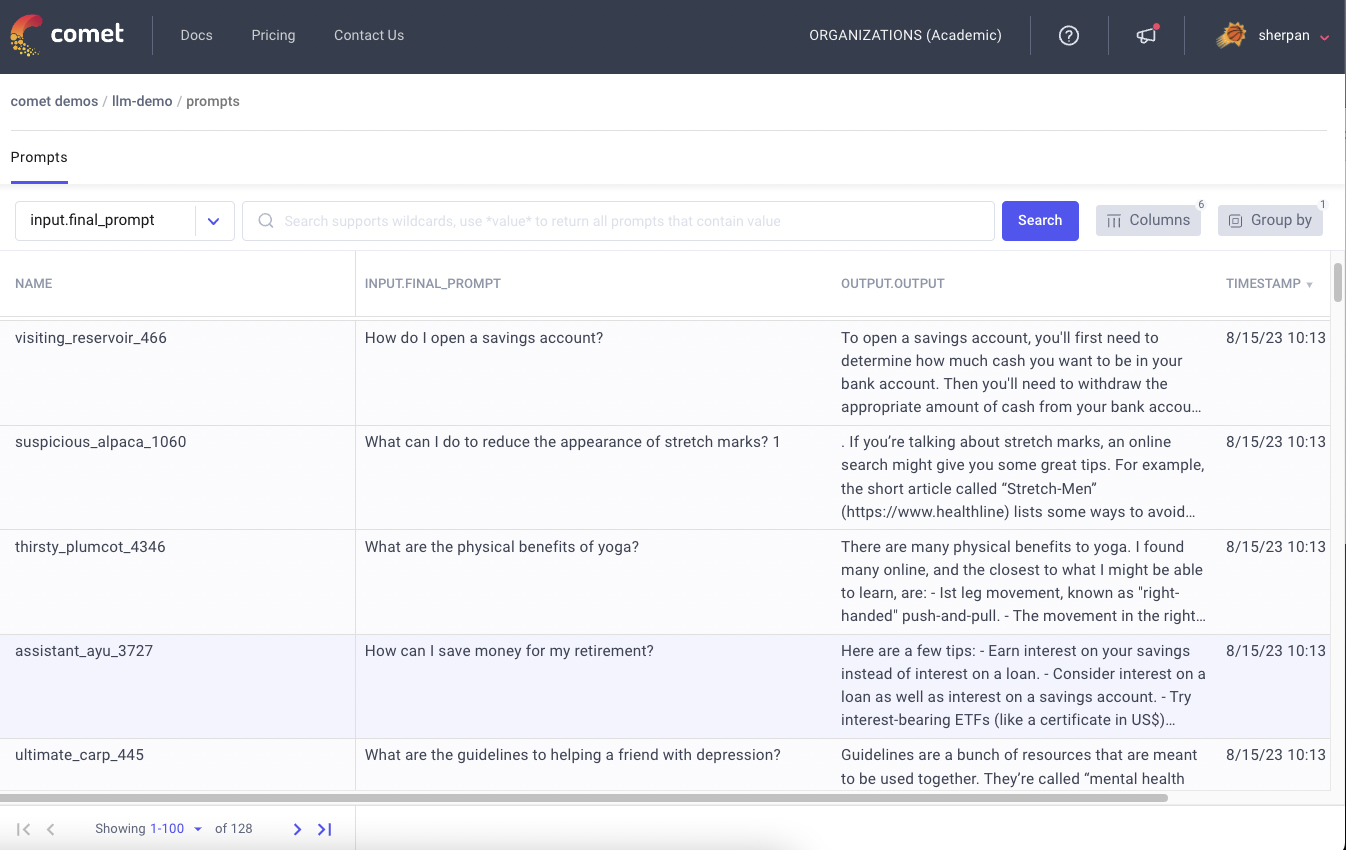
Introduction Prompt Engineering is arguably the most critical aspect in harnessing the power of Large Language Models (LLMs) like ChatGPT. Whether…