Monitoring Spark NLP Pipelines in Comet
Just recently Comet reached another milestone with its integration with Spark NLP. Now you can monitor your NLP experiments directly inside of Comet. Thanks to this integration, you can monitor your NLP pipeline directly in Comet, either during the training process or when it finishes.
Spark NLP is a library for Natural Language Processing released by John Snow Labs. It is 100% open source and supports different programming languages, including Python, Java and Scala. Spark NLP is widely used in production, since it is natively integrated with Apache Spark, a multi-language engine for large-scale analytics.
Spark NLP provides more than 50 features, including Tokenization, Named Entity Recognition, Sentiment Analysis, and much more.
To integrate Spark NLP with Comet, a CometLogger has been added to the Spark NLP library, making it possible to track experiments in a very simple way.
In this article, I give an overview of the CometLogger provided by Spark NLP as well as the steps needed to make a project run. For a complete example, you can refer to the article, entitled New Integration: Comet + Spark NLP by Dhruv Nair, as well as to this Colab notebook.
The CometLogger
The Spark NLP library has been extended with a new subpackage, called comet and available under the logging package:
sparknlp.logging.comet
This subpackage contains a class, named CometLogger, that provides the interface to the Comet platform.
In order to track a Spark NLP experiment, firstly, I create a CometLogger by specifying the Comet configuration parameters, which include the workspace, the project name, and API key:
logger = CometLogger(workspace='my-work-space', project_name='my-project-name', api_key='my-api-key')
The CometLogger class provides different methods that permit to log metrics, parameters, and models, as well as monitor the steps of a training process. The main methods provided by the CometLogger class are below and the description of the method has been taken directly from the documentation:
log_pipeline_parameters(): Iterates over the different stages in a pyspark PipelineModel object and logs the parameters to Comet.log_visualization(): Uploads a NER visualization from Spark NLP Display to Comet.log_metrics(): Submits logs of an evaluation metrics.log_parameters(): Logs a dictionary (or dictionary-like object) of multiple parameterslog_completed_run(): Submit logs of training metrics after a run has completed.log_asset(): Uploads an asset to Comet.monitor(): Monitors the training of the model and submits logs to Comet, given by an interval.
Note the difference between log_completed_run()and monitor(): the first submits metrics when the run is complete, while the second monitors the metrics during the run.
You can always access to the raw experiment class defined in Comet through logger.experiment field.
For the complete list of methods, you can read the documentation.
How to Build a Project
In order to make Spark NLP run with Comet, these steps should be followed:
- Initialize the
CometLogger - Create the Spark NLP Pipeline
- Attach the
CometLoggerto the Spark NLP Annotator Approach - Train the Pipeline
- Show results in Comet
Initialize the CometLogger
Firstly, I log in to Comet and then I create a new Comet project. I add a new experiment and I copy the generated API key, as well as the project name and workspace.

Now, I can create a new CometLogger:
from sparknlp.logging.comet import CometLoggerlogger = CometLogger(workspace='my-work-space', project_name='my-project-name', api_key='my-api-key')
Did you know that Comet is free for students and start-ups? Get started today and learn how to make better models faster.
Create the Spark NLP Pipeline
Now I can create a Spark NLP Pipeline as I usually do. Firstly, I must transform raw data to a DocumentAssembler where I specify the input and output columns, as well an optional cleanup mode. For example, I can use the shrink mode, which removes new lines and tabs as well as merges multiple spaces and blank lines to a single space.
from sparknlp.base import DocumentAssemblerdocument = ( DocumentAssembler() .setInputCol("text") .setOutputCol("document") .setCleanupMode("shrink") )
Then, I can build my pipeline, which can include many steps, such as tokenization, sentence encoding and so on. In order to track the experiment in Comet, the pipeline should include an AnnotatorApproach object, which can be, for example, a SentimentDLApproach or a MultiClassifierDLApproach.
Among the other parameters, for the AnnotatorApproach object, I must set the path where to save logs through the setOutputLogsPath(PATH) method. The output log will be read by the CometLogger during the training process.
The following snippet of code shows how to set the path for the logs for a MultiClassifierDLApproach:
from sparknlp.annotator import MultiClassifierDLApproach()PATH=/path/to/my/directorymultiClassifier = ( MultiClassifierDLApproach() # add other configuration parameters .setOutputLogsPath(PATH) )
Attach the CometLogger to the Spark NLP Annotator Approach
Now I’m ready to connect the CometLogger to the AnnotatorApproach, which is a MultiClassifierDLApproach in my case. It is sufficient to specify the path to the log and the AnnotatorApproach as follows:
logger.monitor(PATH, multiClassifier)
I should specify the previous method only if I want to monitor the model during the training phase. If I want to log the metrics when the training phase is complete, I should use the log_completed_run() method, as specified in the next sections.
Train the Pipeline
Everything is ready to start my experiment. Thus I can build and train the pipeline. The Spark NLP pipeline involves all the steps previously defined, and can be created as follows:
pipeline = Pipeline(stages=[document, ... , multiClassifier])
The three dots must be substituted by the other steps involved in the pipeline, such as tokenization, sentence splitting, and so on.
The pipeline can be trained with the training data:
model = pipeline.fit(trainDataset)
Show Results in Comet
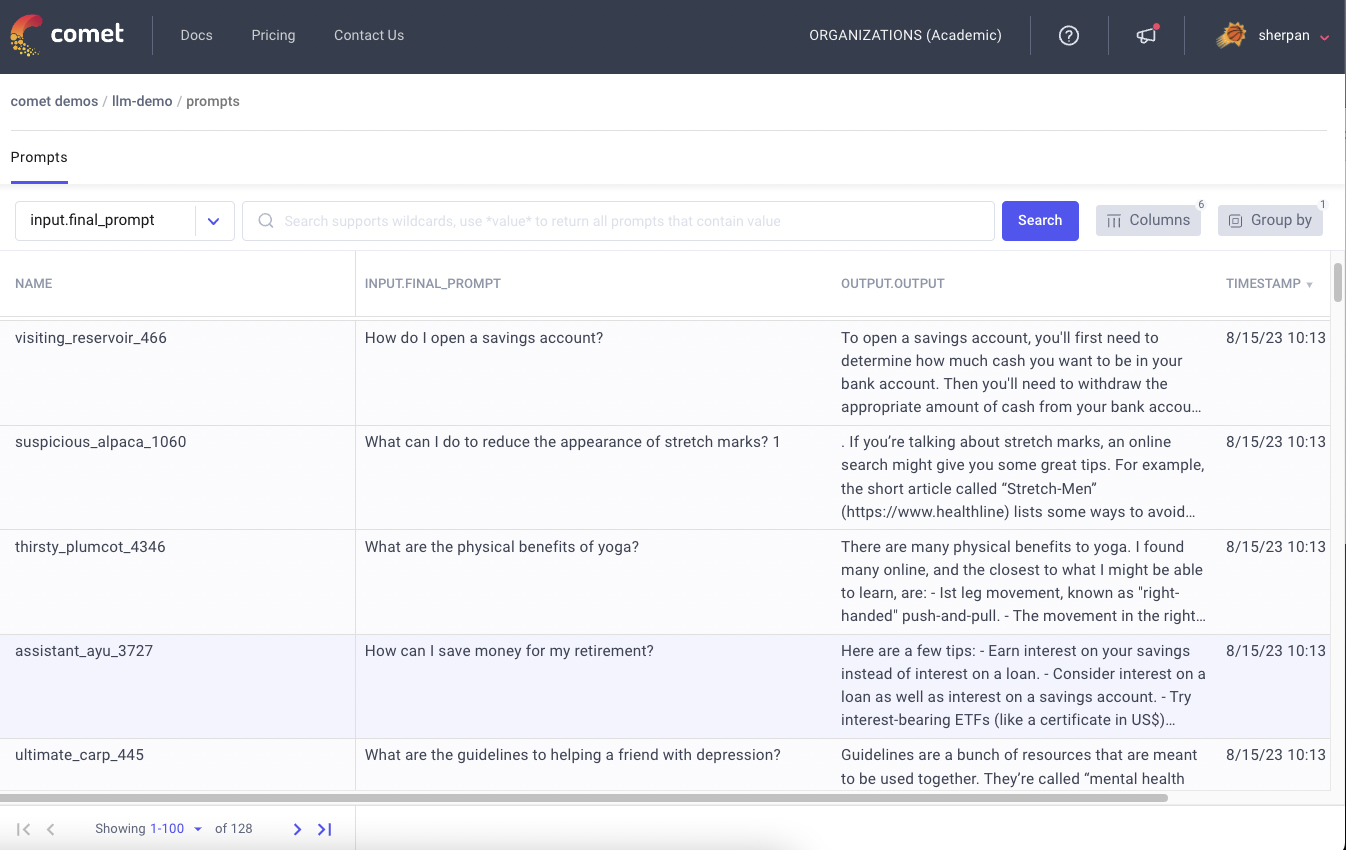
Since I have configured the CometLogger to work with the monitor() method, now I can open the Comet dashboard and look at the experiment results. The following figure shows an example of possible results:

If I don’t want to or I can’t monitor the living training phase, I can still log the training at the end with the log_completed_run() method. In this case, I must pass as the log file produced by the AnnotatorApproach as argument:
logger.log_completed_run('/Path/To/Log/File.log')
Summary
Congratulations, you have learned how to monitor your Spark NLP experiments in Comet! Only give simple steps are needed to make your Spark NLP experiments run in Comet.
If you are not an expert in Comet or you are completely new to it, I suggest you to try it. You will discover many features, such as the possibility to build personalized panels and reports.
Happy coding, happy Comet!
Related Articles