Our mission is to empower practitioners and teams to achieve business value with AI.
Comet builds tools that help data scientists, engineers, and team leaders accelerate and optimize machine learning and deep learning models. Organizations of every size—from academic teams to startups to enterprise companies—use our platform to build better ML models faster.
AI: The Century’s Biggest Opportunity
Despite machine learning’s proven potential to deliver outsized business outcomes, it is a slow, iterative process with many challenges and moving parts. Addressing fundamental pain points and reducing friction in the ML workflow allows data scientists and ML practitioners to share their work, iterate, and reproduce results so they can build better models faster.
VentureBeat, 2022

Gideon Mendels
CEO and Co-founder, Comet
The New ML Development Stack
Today, there is too much distance between machine learning done in academia and creating real value from machine learning initiatives in production environments. Most companies are still trying to figure out their processes and technology stacks, and many are struggling to realize value from their machine learning investment.
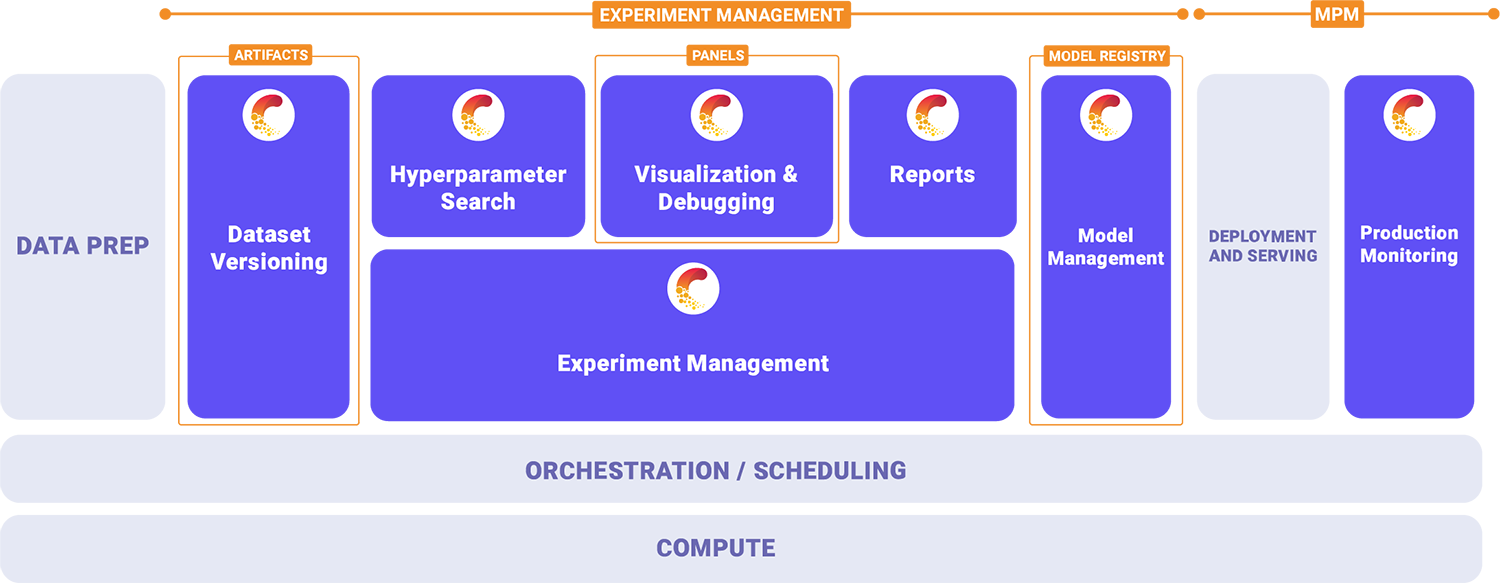
To reduce the friction caused by disconnected ML tech stacks and to help companies realize value from ML, Comet focuses on the three core elements of development: experiment management, model management, and production monitoring. Comet’s highly customizable ML development platform allows data scientists and engineers to manage and optimize models across the entire ML lifecycle in a single user interface.
From Startups to the World's Largest Companies
Hundreds of organizations use Comet’s platform to track, compare, explain, and optimize models from training runs through production. An estimated 70% of people in North America have interacted with a machine learning or deep learning model that was trained using Comet’s platform.